The Rise of Generative AI Large Language Models (LLMs) like ChatGPT
A visualisation of major large-language models (LLMs), ranked by performance, using MMLU (Massive Multitasks Language Understanding) a benchmark for evaluating the capabilities of large language models.
» main source: Life Architect data
» see our data
» chart rendered with VizSweet
notes
The MMLU rating consists of 16,000 multiple-choice questions across 57 academic subject (link)
MMLU has some critiques, mainly that LLM creators may be wise to the metric and be pre-training their models to answer MMLU questions. (New York Times article). And here’s a general cautionary article.
If you’re interested in ongoing metrics, LLMArena has a leaderboard ranked subjectively by tens of thousands of users. Note: it privileges English language LLMs (there are no Chinese models on there for example). Intel also run a leaderboard with many measurements.
Note: we excluded specialised maths and coding LLMs like DeepSeek Coder, Mathstral, Granite Code etc. Let us know if we’ve missed any LLMs.
: 12th Dec – added Amazon Nova Pro, Google Gemini 2.0, Meta’s LLama 3.3, LG’s ExaONE 3.5, and, of course, OpenAI latest interation of o1
: 11th Dec – added requested ‘search’ functionality to viz
: 3rd Nov – updated and created MMLU visualisation
: 31st Oct – added LLMs released since March, including: Anthropic Claude 3.5, Grok 2.0, AMD-Llama, Google’s Gemini 1.5, Meta’s Llama 3.2, OpenAI’s o1 and GPT-4o mini, Pixtral 12b and other offerings from Mistral, Qwen 2.5, EXAONE 3.0, and Apple’s first on device models.
: 31st Oct – new visualisation of LLMs based on MMLU (Massive Multitask Language Understanding) for those models that cite this metric
: 20th Mar 2024 – added 30 new notable LLMs including Anthropic Claude 3, Twitter’s Grok, all Mistral’s offerings, Google Gemini Pro, Apple’s MM1 (finally!) and Chinese LLMs like DeepSeek, GLM-4 and Xinghuo 3.5. The soon-to-be-released column includes OpenAI’s rumoured open source LLM G3PO, Amazon’s mighty Olympus, Meta’s Llama 3 and of course GPT-5.
: 6th Dec 2023 – added 2024 column including Amazon’s Olympus, Anthropic’s Claude-Next and Twitter’s Grok. Also noted the release of Google’s Gemini and Amazon’s Q business bot.
: 21st Nov – added Bichuan 2, Claude Instant, IDEFICS, Jais Chat, Japanese StableLM Alpha 7B, InternLM, Falcon 180B, Bolt 2.5B, DeciLM, Mistral-7B, Persimmon-8B, MoLM, Qwen, AceGPT, Retro48B, Ernie 4.0
: 2nd Nov – updated Amazon story with $1.25bn Anthropic investment
: 27th Jul – added Meta’s LLama2
: 12th Jun – added Claude 2.0, and ErnieBot 3.5
: 21st Jun – added Vicuna 13-B, Falcon LLM, Sail-7B, Web-LLM, OpenLLM
: 20th Jun – visualized all open-source LLMs as a diamond
: 11th Jun – added a ‘more info’ link for each LLM (click to spawn)
: 11th May – added Google’s latest LLM PaLM2 (source)
: 10th May 2023 – Uploaded first version
An earlier graphic of ours
further notes & essential reading
» Why LLMs Can’t Play Wordle and Why That Means They Won’t Lead to AGI
» How ChatGPT and other LLMs Work – And Where They Could Go Next (good Wired article)
» More detailed (understandable) explanation of how LLMs work
» While we’ve plotted these LLMs by the size of each model in billion parameters, there is a growing sense of diminishing returns for simply increasing the model size (Wired article)
» Will A.I. become the new McKinsey? Author Ted Chiang argues that AI is likely to function like larger corporate consulting firms, acting as a “willing executioner”, accelerating job loss (New Yorker)
» The Mounting Environmental & Human Costs of Generative AI (Arstechnica article) &TLDR: larger models = more consumption of planetary resources (minerals, energy, water for cooling) + AI training needs large-scale human supervision so very real possibility of ‘AI sweatshops‘ + the serious issues of copyright infringement for artists and creators.
summarised here: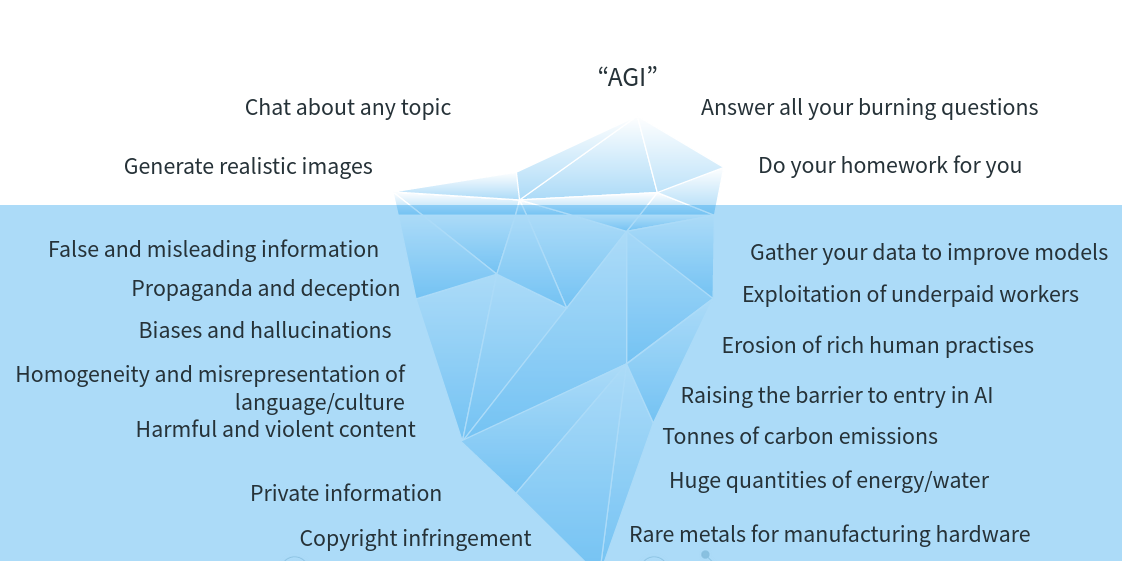
Share this:
A Quick Data Story
Some simple filtering reveals an interesting story in our early LLM data.
Google drove a burst of innovation in the LLM space
Sharing their knowledge and research with the AI world. (Transformers, for example, the ‘T’ in GPT, originated from research at Google). But then the broader company was pipped to the practical-application post by OpenAI. Will their latest release PaLM2 overtake ChatGPT?
OpenAI, creators of ChatGPT, stole the LLM show
They made steady, solid progress over the last three years, driving the curve. Slow and steady won the race?
And here’s why Microsoft invested in OpenAI
You can see they weren’t directly active in the space with their own research. Instead they invested early and hard in OpenAI ($1bn in both 2019 and 2021) and that paid serious dividends.
Meta / Facebook also drove significant early innovation in the field…

What muted their breakthroughs? Maybe the models weren’t large enough (see how many are below the ‘magic’ 175 billion parameter line). Maybe, like Google, there’s was too much emphasis on internal applications & processes versus public tools? Maybe, also, their research was chastened by the poor reception of its science-specialised LLM Galactica.
Meanwhile, in the background, China is also making steady progress
In the advent of ChatGPT, release of Chinese-language LLM’s and chatbots have significantly accelerated.
What about Amazon?
Well, they have steamed in at the end – too late to the party? Time will tell… Though they have recently invested heavily in Anthropic, creators of impressive LLM Claude
